

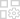






Nhà sản xuất chật pháp nghi ngờ Trung Quốc, Dirt Deep Deep AI Các mô hình AI được xây dựng bằng cách sử dụng dữ liệu OpenAI - và sự trớ trêu không bị mất trên internet
Openai nghi ngờ rằng các mô hình AI Deepseek của Trung Quốc, rẻ hơn đáng kể so với các đối tác phương Tây, có thể đã được đào tạo bằng cách sử dụng dữ liệu Openai, gây tranh cãi và hỗn loạn thị trường. Sự xuất hiện của Deepseek, và mô hình R1 của nó đặc biệt, đã gây ra sự sụt giảm đáng kể về giá cổ phiếu của các công ty lớn liên quan đến AI, với NVIDIA bị mất một ngày lớn nhất trong lịch sử. Deepseek tuyên bố chi phí đào tạo thấp của mô hình (6 triệu đô la) và giảm nhu cầu tính toán là do nền tảng DeepSeek-V3 nguồn mở.
Sự phát triển này đã làm dấy lên mối lo ngại về các khoản đầu tư lớn các công ty công nghệ Mỹ đang đổ vào AI, khiến nhà đầu tư e ngại. Sự phổ biến của Deepseek, đã nhanh chóng đứng đầu các biểu đồ tải xuống ứng dụng của Hoa Kỳ, tiếp tục thúc đẩy những lo lắng này. Openai và Microsoft đang điều tra xem liệu Deepseek có vi phạm các điều khoản dịch vụ của Openai hay không bằng cách sử dụng một kỹ thuật gọi là "chưng cất" - trích xuất dữ liệu từ các mô hình lớn hơn để đào tạo các mô hình nhỏ hơn - sử dụng API của Openai. Openai đã xác nhận nhận thức về những nỗ lực như vậy của Trung Quốc và các công ty khác để tái tạo các mô hình AI dẫn đầu của Hoa Kỳ và tuyên bố cam kết bảo vệ tài sản trí tuệ của mình.
Cố vấn AI của Donald Trump, David Sacks, đã chứng thực những nghi ngờ của Openai, cho rằng các hành động của Deepseek liên quan đến việc trích xuất kiến thức trái phép từ các mô hình Openai. Ông dự đoán rằng các công ty AI hàng đầu sẽ thực hiện các biện pháp để ngăn chặn các trường hợp chưng cất dữ liệu trong tương lai.
Tình huống nêu bật một sự trớ trêu đáng kể: bản thân Openai đã phải đối mặt với những cáo buộc sử dụng tài liệu có bản quyền mà không có sự cho phép trong việc phát triển Chatgpt. Sự giả hình này đã được ghi nhận rộng rãi trên phương tiện truyền thông xã hội, với các nhà phê bình chỉ ra sự khẳng định trước đây của Openai rằng việc tạo ra các công cụ AI như TATGPT mà không có tài liệu có bản quyền là "không thể". Openai đã bảo vệ các hoạt động của mình, trích dẫn việc sử dụng rộng rãi các tài liệu có bản quyền khi cần thiết để đào tạo các mô hình ngôn ngữ lớn và lập luận rằng việc sử dụng nó cấu thành "sử dụng hợp lý". Yêu cầu này hiện đang bị thách thức trong các vụ kiện do tờ New York Times và 17 tác giả đệ trình, cáo buộc vi phạm bản quyền. Cảnh quan pháp lý xung quanh dữ liệu đào tạo AI và bản quyền vẫn được tranh cãi cao, đặc biệt là trong một văn phòng bản quyền năm 2018 của Hoa Kỳ phán quyết rằng nghệ thuật do AI tạo ra không đủ điều kiện để bảo vệ bản quyền.

-
 Dec 25,24Xem trước bản cập nhật Zenless Zone Zero 1.5 Cập nhật Zenless Zone Zero Phiên bản 1.5: Nhân vật biểu ngữ bị rò rỉ được tiết lộ Những rò rỉ mới về Zenless Zone Zero đã tiết lộ đội hình nhân vật cho bản cập nhật Phiên bản 1.5 sắp tới, bao gồm cả những lần chạy lại nhân vật rất được mong đợi. Game nhập vai hành động HoYoverse này tiếp tục mở rộng danh sách các nhân vật mạnh mẽ, fr
Dec 25,24Xem trước bản cập nhật Zenless Zone Zero 1.5 Cập nhật Zenless Zone Zero Phiên bản 1.5: Nhân vật biểu ngữ bị rò rỉ được tiết lộ Những rò rỉ mới về Zenless Zone Zero đã tiết lộ đội hình nhân vật cho bản cập nhật Phiên bản 1.5 sắp tới, bao gồm cả những lần chạy lại nhân vật rất được mong đợi. Game nhập vai hành động HoYoverse này tiếp tục mở rộng danh sách các nhân vật mạnh mẽ, fr -
 May 06,25Cờ vua ma thuật: Hướng dẫn của người mới bắt đầu để làm chủ cơ học cốt lõi Chess Magic: Go Go, một trò chơi chiến lược tự động nổi bật được tạo ra bởi Moonton, bắt nguồn sâu sắc trong vũ trụ sôi động của các huyền thoại di động. Trò chơi này kết hợp một cách thuần thục các chiến thuật cờ vua với các chiến lược dựa trên anh hùng, mang đến cho người chơi cơ hội tạo ra các đội ngũ đội ngũ đáng gờm có sự tham gia của các anh hùng từ Th
May 06,25Cờ vua ma thuật: Hướng dẫn của người mới bắt đầu để làm chủ cơ học cốt lõi Chess Magic: Go Go, một trò chơi chiến lược tự động nổi bật được tạo ra bởi Moonton, bắt nguồn sâu sắc trong vũ trụ sôi động của các huyền thoại di động. Trò chơi này kết hợp một cách thuần thục các chiến thuật cờ vua với các chiến lược dựa trên anh hùng, mang đến cho người chơi cơ hội tạo ra các đội ngũ đội ngũ đáng gờm có sự tham gia của các anh hùng từ Th -
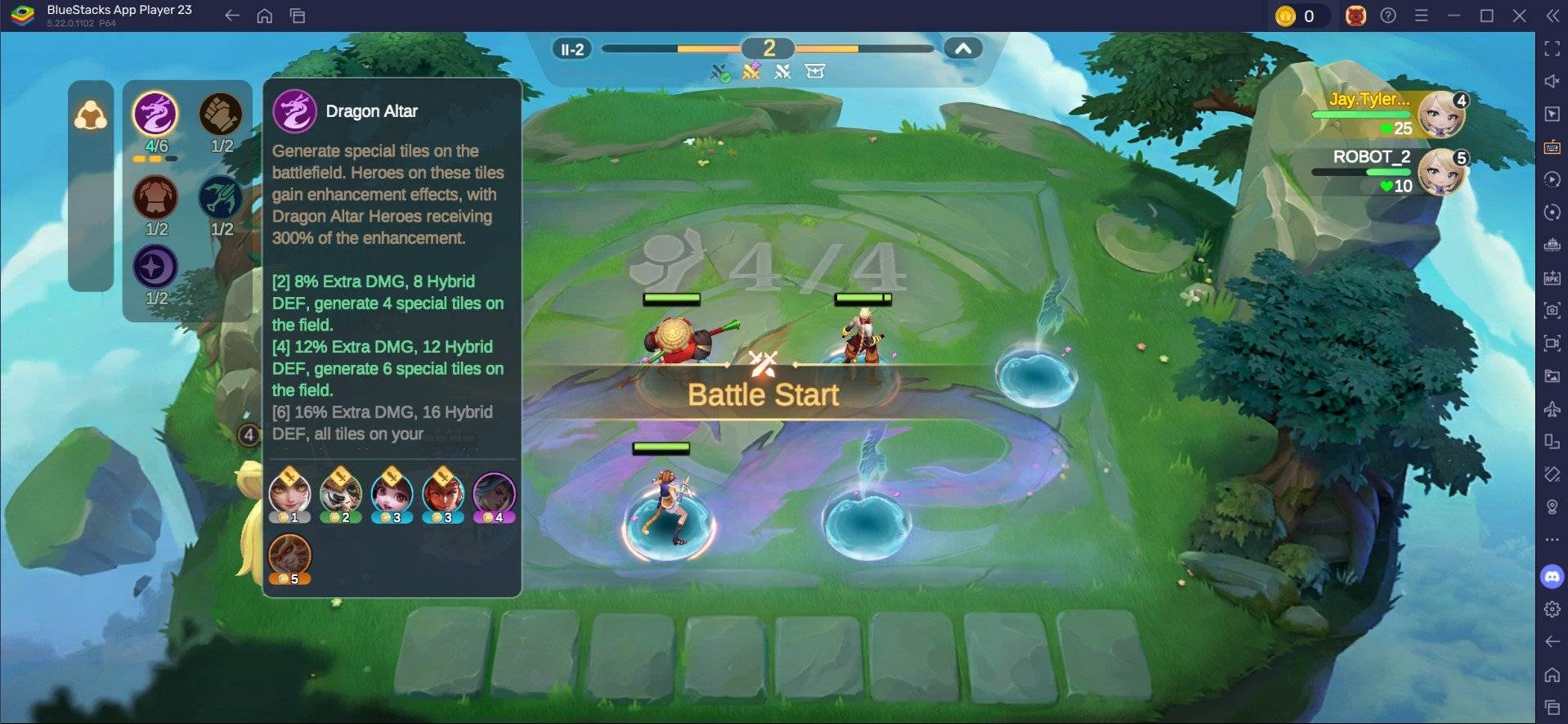
 Jan 18,25Roblox Grace: Tất cả các lệnh và cách sử dụng chúng Liên kết nhanhTất cả các lệnh GraceCách sử dụng các lệnh GraceGrace là một trải nghiệm Roblox trong đó bạn sẽ phải điều hướng qua nhiều cấp độ khác nhau với các thực thể đáng sợ đang chờ bạn. Trò chơi này khá khó khăn vì bạn sẽ cần phải nhanh nhẹn và phản ứng nhanh cũng như tìm cách chống lại kẻ thù.
Jan 18,25Roblox Grace: Tất cả các lệnh và cách sử dụng chúng Liên kết nhanhTất cả các lệnh GraceCách sử dụng các lệnh GraceGrace là một trải nghiệm Roblox trong đó bạn sẽ phải điều hướng qua nhiều cấp độ khác nhau với các thực thể đáng sợ đang chờ bạn. Trò chơi này khá khó khăn vì bạn sẽ cần phải nhanh nhẹn và phản ứng nhanh cũng như tìm cách chống lại kẻ thù. -
 Apr 11,25"Danh sách các anh hùng hàng đầu cho các câu đố & sinh tồn vào năm 2025" Một danh sách cấp cho các câu đố & sinh tồn là một công cụ thiết yếu cho người chơi muốn tối ưu hóa lối chơi của họ. Nó giúp xác định các anh hùng hiệu quả nhất cho các chế độ trò chơi khác nhau, chẳng hạn như trận chiến trận 3, phòng thủ căn cứ và chiến đấu PVP. Đưa ra một loạt các anh hùng của trò chơi, xếp hạng chúng theo th
Apr 11,25"Danh sách các anh hùng hàng đầu cho các câu đố & sinh tồn vào năm 2025" Một danh sách cấp cho các câu đố & sinh tồn là một công cụ thiết yếu cho người chơi muốn tối ưu hóa lối chơi của họ. Nó giúp xác định các anh hùng hiệu quả nhất cho các chế độ trò chơi khác nhau, chẳng hạn như trận chiến trận 3, phòng thủ căn cứ và chiến đấu PVP. Đưa ra một loạt các anh hùng của trò chơi, xếp hạng chúng theo th