

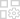






O fabricante de chatgpt suspeita
Openai suspeita que os modelos Deepseek AI da China, significativamente mais baratos que os colegas ocidentais, podem ter sido treinados usando dados do OpenAI, provocando controvérsia e turbulência do mercado. O surgimento da Deepseek e seu modelo R1 especificamente causaram uma queda dramática nos preços das ações das principais empresas relacionadas à IA, com a Nvidia experimentando sua maior perda de história em um dia. A Deepseek afirma que o baixo custo de treinamento do seu modelo (US $ 6 milhões) e as necessidades computacionais reduzidas são devidas à sua fundação de código aberto Deepseek-V3.
Esse desenvolvimento levantou preocupações sobre os enormes investimentos americanos que as empresas de tecnologia estão investigando a IA, levando a apreensão dos investidores. A popularidade da Deepseek, que rapidamente cobriu as paradas de download de aplicativos, alimentou ainda mais essas ansiedades. O OpenAI e a Microsoft estão investigando se Deepseek violou os termos de serviço da OpenAI, empregando uma técnica chamada "destilação" - extraindo dados de modelos maiores para treinar os menores - usando a API do OpenAI. A OpenAI confirmou sua conscientização sobre tais tentativas dos chineses e de outras empresas de replicar os modelos de IA nos EUA e declarou seu compromisso de proteger sua propriedade intelectual.
O conselheiro de AI de Donald Trump, David Sacks, corroborou as suspeitas do Openai, sugerindo que as ações de Deepseek envolviam a extração não autorizada do conhecimento dos modelos Openai. Ele antecipa que as principais empresas de IA implementarão medidas para evitar futuras instâncias de destilação de dados.
A situação destaca uma ironia significativa: o próprio Openi enfrentou acusações de usar material protegido por direitos autorais sem autorização no desenvolvimento do ChatGPT. Essa hipocrisia tem sido amplamente observada nas mídias sociais, com críticos apontando para a afirmação anterior do OpenAI de que a criação de ferramentas de IA como o ChatGPT sem material protegido por direitos autorais é "impossível". A Openai defendeu suas práticas, citando o uso extensivo de material protegido por direitos autorais, conforme necessário para treinar grandes modelos de idiomas e argumentar que seu uso constitui "uso justo". Atualmente, esta reclamação está sendo desafiada em ações movidas pelo New York Times e 17 autores, alegando violação de direitos autorais. O cenário legal em torno dos dados de treinamento e direitos autorais de IA permanece altamente contestado, particularmente à luz de um escritório de direitos autorais dos EUA em 2018, que decidiu que a arte gerada pela IA não é elegível para a proteção de direitos autorais.

-
 Dec 25,24Pré-visualização da atualização do Zenless Zone Zero 1.5 Atualização do Zenless Zone Zero versão 1.5: caracteres de banner vazados revelados Novos vazamentos para Zenless Zone Zero revelam a programação de personagens para a próxima atualização da versão 1.5, incluindo reprises de personagens altamente antecipadas. Este RPG de ação HoYoverse continua a expandir sua lista de personagens poderosos, de
Dec 25,24Pré-visualização da atualização do Zenless Zone Zero 1.5 Atualização do Zenless Zone Zero versão 1.5: caracteres de banner vazados revelados Novos vazamentos para Zenless Zone Zero revelam a programação de personagens para a próxima atualização da versão 1.5, incluindo reprises de personagens altamente antecipadas. Este RPG de ação HoYoverse continua a expandir sua lista de personagens poderosos, de -
 May 06,25Chess Magic: Guia para iniciantes para dominar a mecânica do núcleo Chess Magic: Go Go, um emocionante jogo de estratégia de batalha automática criada por Moonton, está profundamente enraizada no universo vibrante de lendas móveis. Este jogo combina magistralmente táticas de xadrez com estratégias baseadas em heróis, oferecendo aos jogadores a chance de criar formidáveis formidáveis de equipe com heróis do TH
May 06,25Chess Magic: Guia para iniciantes para dominar a mecânica do núcleo Chess Magic: Go Go, um emocionante jogo de estratégia de batalha automática criada por Moonton, está profundamente enraizada no universo vibrante de lendas móveis. Este jogo combina magistralmente táticas de xadrez com estratégias baseadas em heróis, oferecendo aos jogadores a chance de criar formidáveis formidáveis de equipe com heróis do TH -
 Apr 08,25Top Free Fire Personagens 2025: Ultimate Guide O Free Fire, criado por Garena, consolidou seu status de jogo de Battle Royale de primeira linha, acumulando mais de 1 bilhão de downloads na Google Play Store e envolvendo milhões de jogadores ativos diários. Seu apelo está não apenas em sua jogabilidade emocionante, mas também em sua diversidade de personagens,
Apr 08,25Top Free Fire Personagens 2025: Ultimate Guide O Free Fire, criado por Garena, consolidou seu status de jogo de Battle Royale de primeira linha, acumulando mais de 1 bilhão de downloads na Google Play Store e envolvendo milhões de jogadores ativos diários. Seu apelo está não apenas em sua jogabilidade emocionante, mas também em sua diversidade de personagens, -
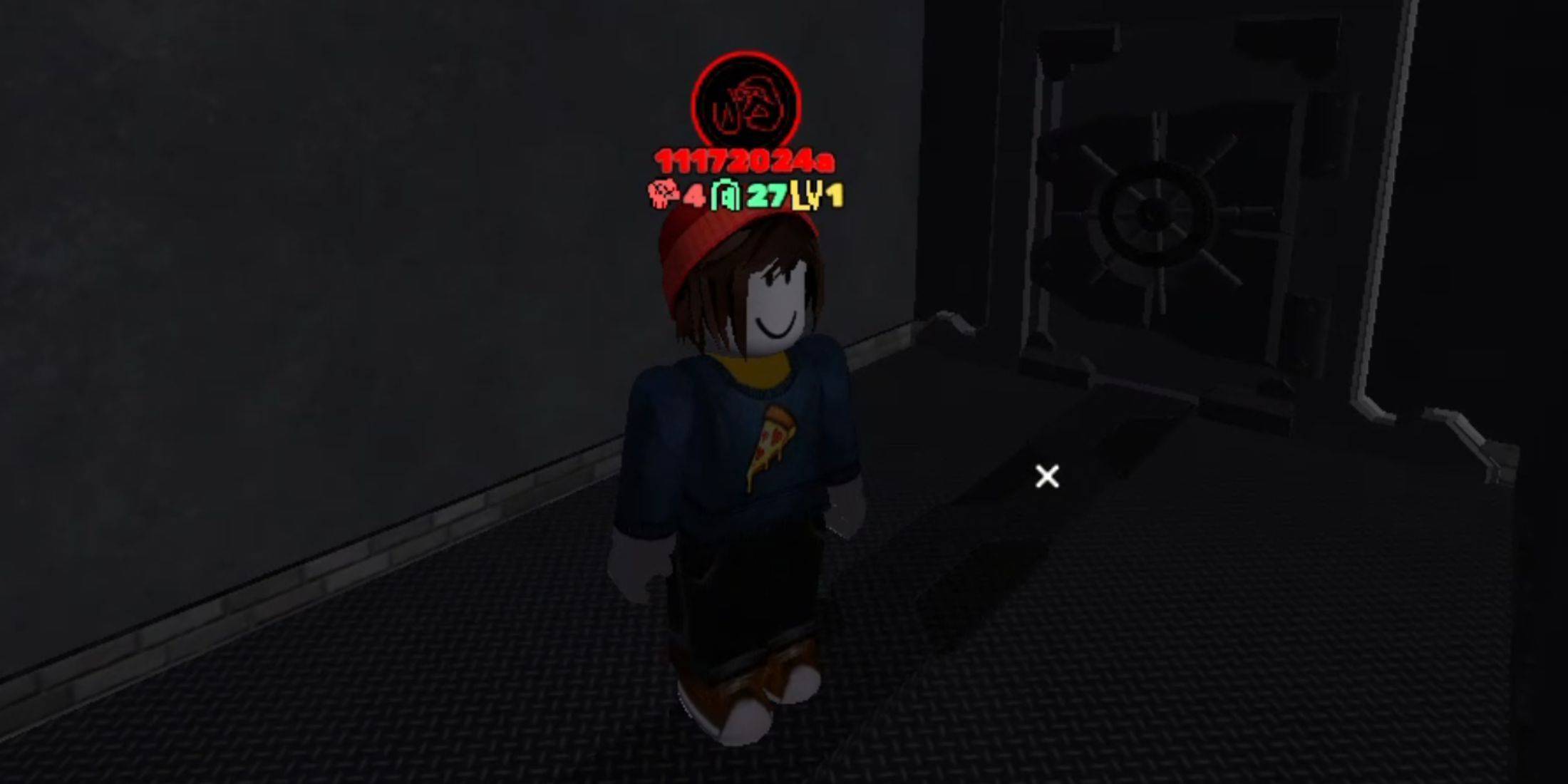 Jan 18,25Roblox Grace: todos os comandos e como usá-los Links rápidosTodos os comandos GraceComo usar os comandos GraceGrace é uma experiência Roblox onde você terá que navegar por vários níveis com entidades assustadoras esperando por você. Este jogo é bastante desafiador, pois você precisará ser rápido e reagir rapidamente, além de procurar maneiras de neutralizar a entidade.
Jan 18,25Roblox Grace: todos os comandos e como usá-los Links rápidosTodos os comandos GraceComo usar os comandos GraceGrace é uma experiência Roblox onde você terá que navegar por vários níveis com entidades assustadoras esperando por você. Este jogo é bastante desafiador, pois você precisará ser rápido e reagir rapidamente, além de procurar maneiras de neutralizar a entidade.