

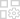






Il produttore di chatgpt sospetta che i modelli di AI Deep -Seek di Dirt Economico della Cina siano stati costruiti utilizzando i dati OpenAI - e l'ironia non è persa su Internet
Openai sospetta che i modelli di AI Deepseek della Cina, significativamente più economici delle controparti occidentali, possano essere state addestrate utilizzando i dati aperti, scatenando polemiche e turbolenze di mercato. L'emergere di DeepSeek, e il suo modello R1 in particolare, ha causato un drammatico calo dei prezzi delle azioni delle principali società legate all'intelligenza artificiale, con Nvidia che ha registrato la sua più grande perdita di un giorno nella storia. DeepSeek afferma che il basso costo del suo modello ($ 6 milioni) e le esigenze computazionali ridotte sono dovute alla sua fondazione Open-Source Deepseek-V3.
Questo sviluppo ha sollevato preoccupazioni per i massicci investimenti che le società tecnologiche americane si stanno riversando nell'intelligenza artificiale, spingendo l'apprensione degli investitori. La popolarità di DeepSeek, che ha rapidamente in cima a noi grafici per il download delle app, alimentava ulteriormente queste ansie. Openai e Microsoft stanno studiando se DeepSeek abbia violato i termini di servizio di Openai impiegando una tecnica chiamata "distillazione" - estrarre dati da modelli più grandi per addestrare quelli più piccoli, usando l'API di Openi. Openai ha confermato la sua consapevolezza di tali tentativi da parte dei cinesi e di altre società di replicare i modelli di AI conducente e ha dichiarato il suo impegno a proteggere la sua proprietà intellettuale.
Il consulente di intelligenza artificiale di Donald Trump, David Sacks, ha corroborato i sospetti di Openi, suggerendo che le azioni di Deepseek hanno coinvolto l'estrazione non autorizzata di conoscenze dai modelli Openai. Prevede che le principali società di intelligenza artificiale implementeranno misure per prevenire future istanze di distillazione dei dati.
La situazione evidenzia una significativa ironia: Openai stessa ha affrontato accuse di utilizzare materiale protetto da copyright senza autorizzazione nello sviluppo di CHATGPT. Questa ipocrisia è stata ampiamente notata sui social media, con i critici che indicano l'affermazione precedente di Openi secondo cui la creazione di strumenti di intelligenza artificiale come Chatgpt senza materiale protetto da copyright è "impossibile". Openai ha difeso le sue pratiche, citando l'uso ampio del materiale protetto da copyright, se necessario per la formazione di modelli di grandi dimensioni e sostenendo che il suo uso costituisce "uso equo". Questa affermazione è attualmente sfidata nelle azioni legali presentate dal New York Times e 17 autori, sostenendo una violazione del copyright. Il panorama legale che circonda i dati di addestramento dell'IA e il copyright rimane altamente contestato, in particolare alla luce di una sentenza dell'ufficio del copyright degli Stati Uniti del 2018 che l'arte generata dall'IA non è idonea per la protezione del copyright.

-
 Dec 25,24Anteprima dell'aggiornamento Zenless Zone Zero 1.5 Aggiornamento Zenless Zone Zero versione 1.5: rivelati i personaggi dei banner trapelati Nuove fughe di notizie per Zenless Zone Zero svelano la formazione dei personaggi per il prossimo aggiornamento della versione 1.5, comprese le tanto attese repliche dei personaggi. Questo gioco di ruolo d'azione HoYoverse continua ad espandere il suo elenco di potenti personaggi, fr
Dec 25,24Anteprima dell'aggiornamento Zenless Zone Zero 1.5 Aggiornamento Zenless Zone Zero versione 1.5: rivelati i personaggi dei banner trapelati Nuove fughe di notizie per Zenless Zone Zero svelano la formazione dei personaggi per il prossimo aggiornamento della versione 1.5, comprese le tanto attese repliche dei personaggi. Questo gioco di ruolo d'azione HoYoverse continua ad espandere il suo elenco di potenti personaggi, fr -
 May 06,25Magic Chess: Guida per principianti al padronanza della meccanica principale Magic Chess: Go Go, un esaltante gioco di strategia di battler-battler realizzato da Moonton, è profondamente radicato nell'universo vibrante delle leggende mobili. Questo gioco fonde magistralmente le tattiche di scacchi con strategie basate su Hero, offrendo ai giocatori la possibilità di creare formidabili line-up di squadra con eroi di TH
May 06,25Magic Chess: Guida per principianti al padronanza della meccanica principale Magic Chess: Go Go, un esaltante gioco di strategia di battler-battler realizzato da Moonton, è profondamente radicato nell'universo vibrante delle leggende mobili. Questo gioco fonde magistralmente le tattiche di scacchi con strategie basate su Hero, offrendo ai giocatori la possibilità di creare formidabili line-up di squadra con eroi di TH -
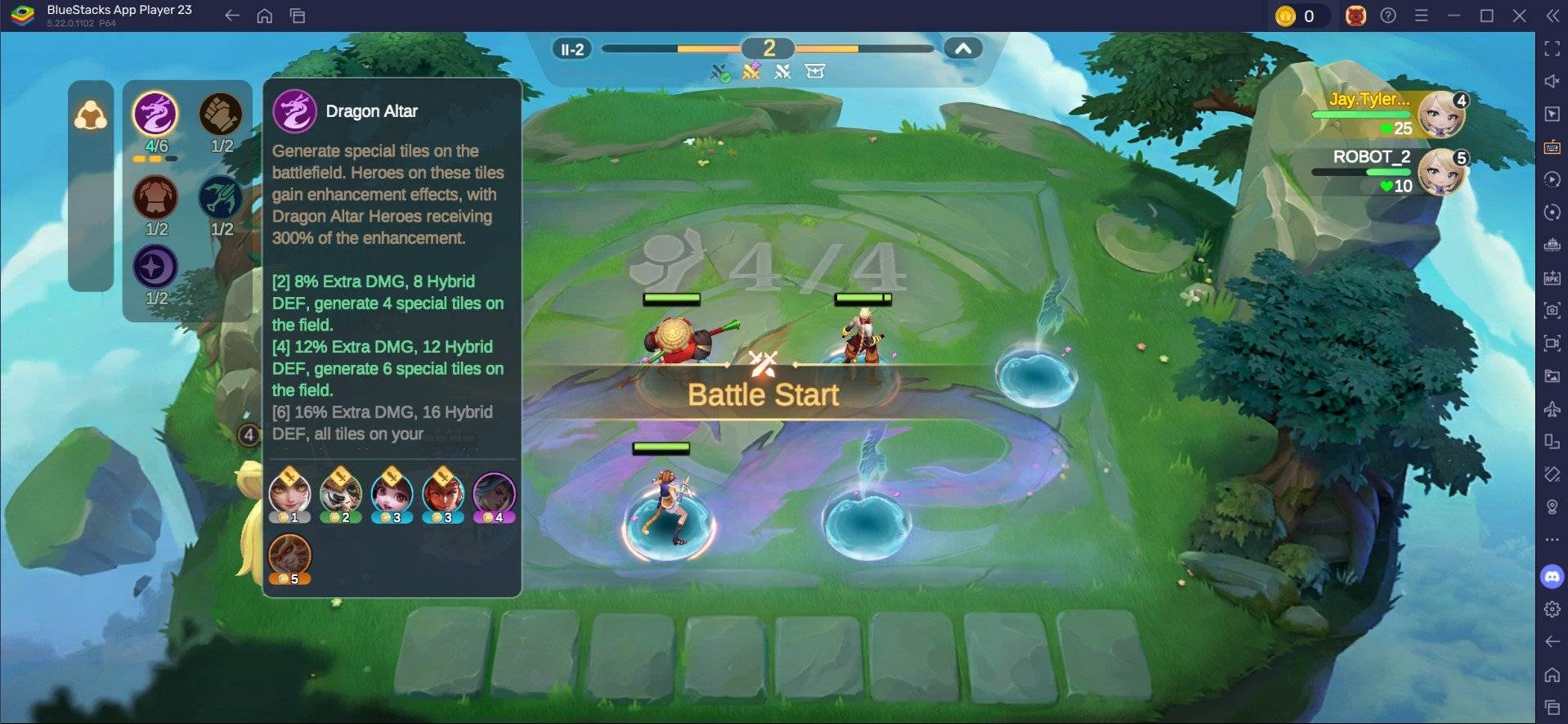
 Jan 18,25Roblox Grace: tutti i comandi e come usarli Collegamenti rapidiTutti i comandi GraceCome utilizzare i comandi GraceGrace è un'esperienza Roblox in cui dovrai navigare attraverso vari livelli con entità spaventose che ti aspettano. Questo gioco è piuttosto impegnativo, poiché dovrai essere veloce e reagire velocemente, oltre a cercare modi per contrastare l'entità
Jan 18,25Roblox Grace: tutti i comandi e come usarli Collegamenti rapidiTutti i comandi GraceCome utilizzare i comandi GraceGrace è un'esperienza Roblox in cui dovrai navigare attraverso vari livelli con entità spaventose che ti aspettano. Questo gioco è piuttosto impegnativo, poiché dovrai essere veloce e reagire velocemente, oltre a cercare modi per contrastare l'entità -
 Apr 11,25"Top Heroes Tier Elenco per enigmi e sopravvivenza nel 2025" Un elenco di livello per puzzle e sopravvivenza è uno strumento essenziale per i giocatori che desiderano ottimizzare il loro gameplay. Aiuta a identificare gli eroi più efficaci per le varie modalità di gioco, come battaglie match-3, difesa di base e combattimento PVP. Data la vasta gamma di eroi del gioco, classificandoli secondo TH
Apr 11,25"Top Heroes Tier Elenco per enigmi e sopravvivenza nel 2025" Un elenco di livello per puzzle e sopravvivenza è uno strumento essenziale per i giocatori che desiderano ottimizzare il loro gameplay. Aiuta a identificare gli eroi più efficaci per le varie modalità di gioco, come battaglie match-3, difesa di base e combattimento PVP. Data la vasta gamma di eroi del gioco, classificandoli secondo TH