

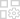






Pinaghihinalaan ng Chatgpt Maker Suspect ang Dirt Murang Deepseek AI Models ay itinayo gamit ang data ng OpenAI - at ang kabalintunaan ay hindi nawala sa internet
Pinaghihinalaan ni Openai na ang mga modelo ng Deepseek AI ng China, na makabuluhang mas mura kaysa sa mga katapat na Kanluranin, ay maaaring sinanay gamit ang data ng OpenAI, na nagpapalabas ng kontrobersya at kaguluhan sa merkado. Ang paglitaw ng Deepseek, at ang modelo ng R1 na partikular, ay nagdulot ng isang dramatikong pagbagsak sa mga presyo ng stock ng mga pangunahing kumpanya na may kaugnayan sa AI, na may nvidia na nakakaranas ng pinakamalaking pagkawala ng solong araw sa kasaysayan. Inaangkin ng Deepseek ang mababang gastos sa pagsasanay ng modelo ($ 6 milyon) at nabawasan ang mga pangangailangan sa computational ay dahil sa open-source deepseek-v3 na pundasyon.
Ang pag -unlad na ito ay nagtaas ng mga alalahanin tungkol sa napakalaking pamumuhunan ng mga kumpanya ng tech na Amerikano na nagbubuhos sa AI, na nag -uudyok sa pang -aabuso sa mamumuhunan. Ang katanyagan ng Deepseek, na mabilis na nanguna sa amin ng mga tsart sa pag -download ng app, ay karagdagang nag -fuel sa mga pagkabalisa na ito. Sinisiyasat ng OpenAI at Microsoft kung nilabag ng Deepseek ang mga termino ng serbisyo ng OpenAi sa pamamagitan ng paggamit ng isang pamamaraan na tinatawag na "distillation" - pagkuha ng data mula sa mas malalaking mga modelo upang sanayin ang mas maliit - gamit ang API ng OpenAI. Kinumpirma ni Openai ang kamalayan ng naturang mga pagtatangka ng mga Tsino at iba pang mga kumpanya upang magtiklop ng nangungunang mga modelo ng US AI at sinabi ang pangako nito na protektahan ang intelektuwal na pag -aari nito.
Ang tagapayo ng AI ni Donald Trump na si David Sacks, na -corroborated na mga hinala ni Openai, na nagmumungkahi na ang mga aksyon ng Deepseek ay kasangkot sa hindi awtorisadong pagkuha ng kaalaman mula sa mga modelo ng OpenAI. Inaasahan niya na ang mga nangungunang kumpanya ng AI ay magpapatupad ng mga hakbang upang maiwasan ang mga pagkakataon sa hinaharap ng data distillation.
Ang sitwasyon ay nagtatampok ng isang makabuluhang irony: Ang OpenAi mismo ay nahaharap sa mga akusasyon ng paggamit ng materyal na copyright na walang pahintulot sa pagbuo ng ChatGPT. Ang pagkukunwari na ito ay malawak na nabanggit sa social media, na may mga kritiko na tumuturo sa nakaraang pagsasaalang -alang ni Openai na ang paglikha ng mga tool ng AI tulad ng Chatgpt nang walang copyright na materyal ay "imposible." Ipinagtanggol ng OpenAI ang mga kasanayan nito, na binabanggit ang malawak na paggamit ng materyal na may copyright kung kinakailangan para sa pagsasanay ng mga malalaking modelo ng wika at pagtatalo na ang paggamit nito ay bumubuo ng "patas na paggamit." Ang paghahabol na ito ay kasalukuyang hinamon sa mga demanda na isinampa ng New York Times at 17 na may -akda, na nagsasaad ng paglabag sa copyright. Ang ligal na landscape na nakapalibot sa data ng pagsasanay sa AI at copyright ay nananatiling lubos na pinagtatalunan, lalo na sa isang 2018 US Copyright Office na naghaharing ang AI-generated art ay hindi karapat-dapat para sa proteksyon ng copyright.

-
 Dec 25,24Zenless Zone Zero 1.5 Update Preview Zenless Zone Zero Bersyon 1.5 Update: Naihayag ang Mga Leak na Karakter ng Banner Ang mga bagong leaks para sa Zenless Zone Zero ay naglalabas ng lineup ng character para sa paparating na Bersyon 1.5 update, kabilang ang inaabangang pag-rerun ng character. Ang HoYoverse action RPG na ito ay patuloy na nagpapalawak ng hanay ng makapangyarihang mga character, fr
Dec 25,24Zenless Zone Zero 1.5 Update Preview Zenless Zone Zero Bersyon 1.5 Update: Naihayag ang Mga Leak na Karakter ng Banner Ang mga bagong leaks para sa Zenless Zone Zero ay naglalabas ng lineup ng character para sa paparating na Bersyon 1.5 update, kabilang ang inaabangang pag-rerun ng character. Ang HoYoverse action RPG na ito ay patuloy na nagpapalawak ng hanay ng makapangyarihang mga character, fr -
 May 06,25Magic Chess: Gabay ng nagsisimula sa Mastering Core Mechanics Magic Chess: Go Go, isang nakakaaliw na diskarte sa diskarte ng auto-battler na ginawa ni Moonton, ay malalim na nakaugat sa masiglang uniberso ng mga mobile alamat. Ang larong ito ay mahusay na pinaghalo ang mga taktika ng chess na may mga diskarte na nakabase sa bayani, na nag-aalok ng mga manlalaro ng pagkakataon na likhain ang mga nakamamanghang line-up ng koponan na nagtatampok ng mga bayani mula sa th
May 06,25Magic Chess: Gabay ng nagsisimula sa Mastering Core Mechanics Magic Chess: Go Go, isang nakakaaliw na diskarte sa diskarte ng auto-battler na ginawa ni Moonton, ay malalim na nakaugat sa masiglang uniberso ng mga mobile alamat. Ang larong ito ay mahusay na pinaghalo ang mga taktika ng chess na may mga diskarte na nakabase sa bayani, na nag-aalok ng mga manlalaro ng pagkakataon na likhain ang mga nakamamanghang line-up ng koponan na nagtatampok ng mga bayani mula sa th -
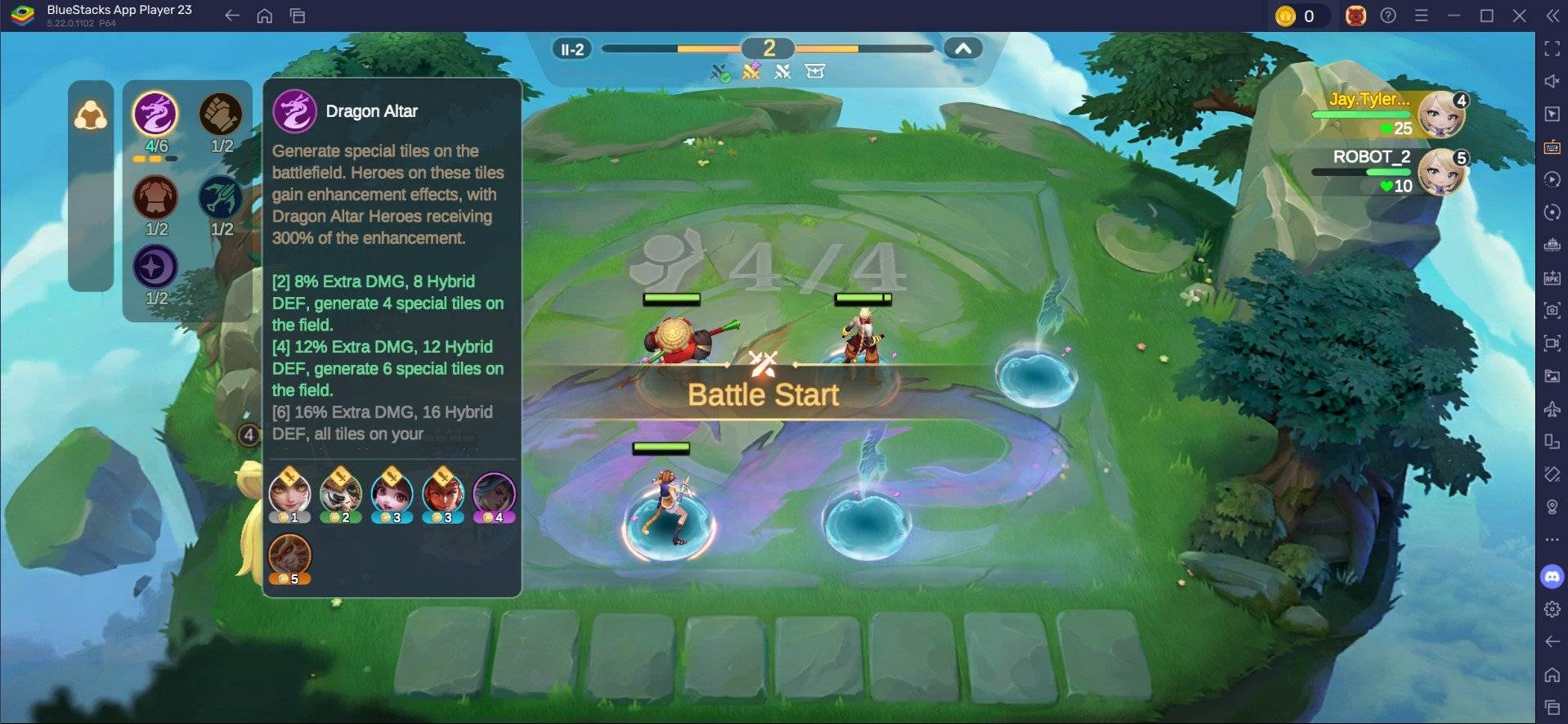
 Jan 18,25Roblox Grace: Lahat ng Utos at Paano Gamitin ang mga Ito Mga Mabilisang LinkAll Grace CommandsPaano Gamitin ang Grace CommandsGrace ay isang Roblox na karanasan kung saan kakailanganin mong mag-navigate sa iba't ibang antas na may mga nakakatakot na entity na naghihintay sa iyo. Ang larong ito ay medyo mapaghamong, dahil kakailanganin mong maging mabilis at mabilis na mag-react, pati na rin maghanap ng mga paraan upang kontrahin ang entit.
Jan 18,25Roblox Grace: Lahat ng Utos at Paano Gamitin ang mga Ito Mga Mabilisang LinkAll Grace CommandsPaano Gamitin ang Grace CommandsGrace ay isang Roblox na karanasan kung saan kakailanganin mong mag-navigate sa iba't ibang antas na may mga nakakatakot na entity na naghihintay sa iyo. Ang larong ito ay medyo mapaghamong, dahil kakailanganin mong maging mabilis at mabilis na mag-react, pati na rin maghanap ng mga paraan upang kontrahin ang entit. -
 Apr 11,25"Nangungunang Listahan ng Mga Bayani para sa Mga Puzzle & Survival sa 2025" Ang isang listahan ng tier para sa mga puzzle at kaligtasan ay isang mahalagang tool para sa mga manlalaro na naghahanap upang ma -optimize ang kanilang gameplay. Nakakatulong ito sa pagkilala sa pinaka-epektibong bayani para sa iba't ibang mga mode ng laro, tulad ng mga laban sa 3, batayang pagtatanggol, at labanan ng PVP. Ibinigay ang malawak na hanay ng mga bayani, na nagraranggo sa kanila ayon sa ika
Apr 11,25"Nangungunang Listahan ng Mga Bayani para sa Mga Puzzle & Survival sa 2025" Ang isang listahan ng tier para sa mga puzzle at kaligtasan ay isang mahalagang tool para sa mga manlalaro na naghahanap upang ma -optimize ang kanilang gameplay. Nakakatulong ito sa pagkilala sa pinaka-epektibong bayani para sa iba't ibang mga mode ng laro, tulad ng mga laban sa 3, batayang pagtatanggol, at labanan ng PVP. Ibinigay ang malawak na hanay ng mga bayani, na nagraranggo sa kanila ayon sa ika