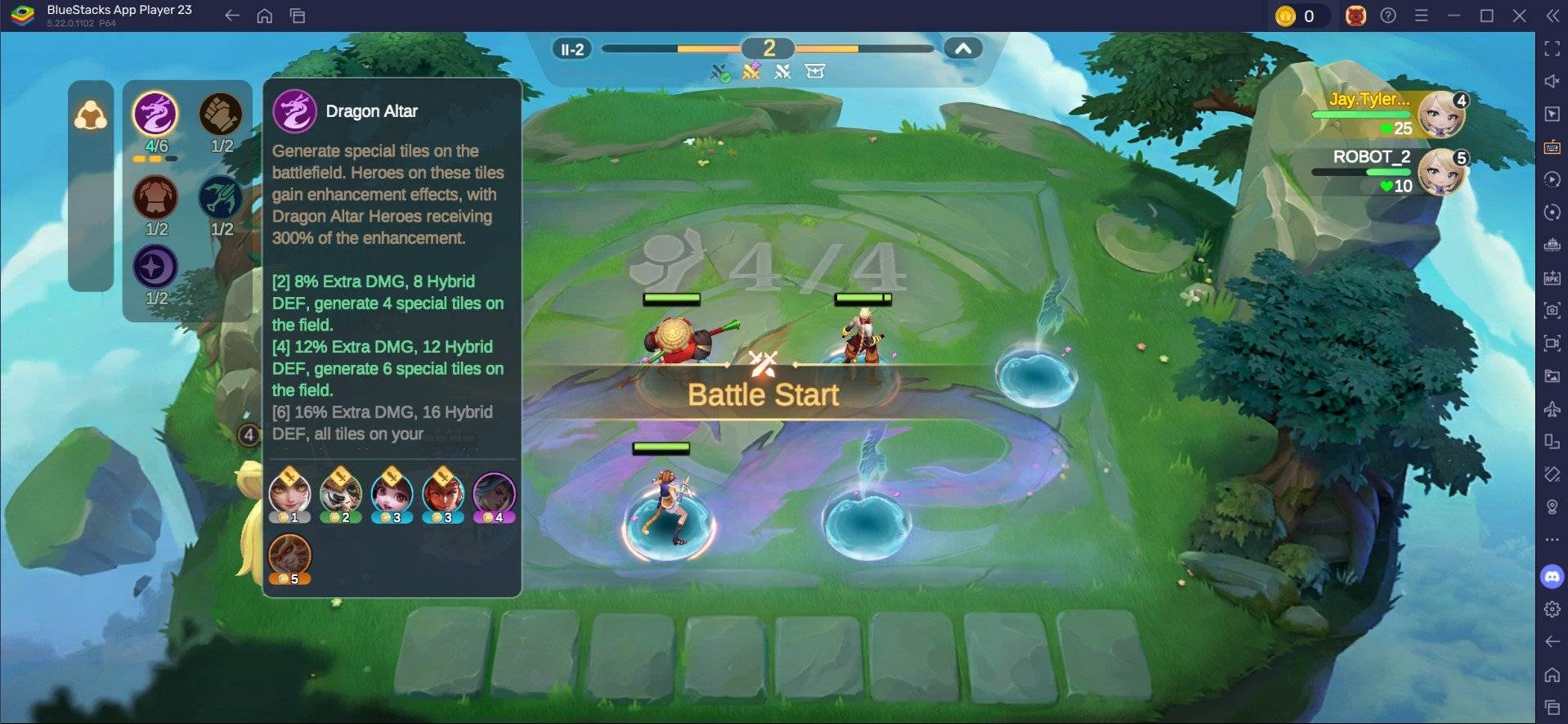






Chatgpt Maker懷疑中國的汙垢廉價DeepSeek AI模型是使用OpenAI數據建造的,而具有諷刺意味
Openai懷疑中國的DeepSeek AI模型比西方同行便宜得多,可能已經使用OpenAI數據進行了培訓,引發了爭議和市場動蕩。 DeepSeek及其R1模型的出現使主要AI相關公司的股票價格急劇下降,NVIDIA經曆了其曆史上最大的單日損失。 DeepSeek聲稱其模型的低培訓成本(600萬美元),計算需求減少是由於其開源DeepSeek-V3基金會。
這一發展引起了人們對美國科技公司正在湧入AI的大規模投資的擔憂,促使投資者擔心。 DeepSeek的受歡迎程度迅速超過了我們的應用程序下載圖表,進一步加劇了這些焦慮。 Openai和Microsoft正在調查DeepSeek是否使用一種稱為“蒸餾”的技術違反了OpenAI的服務條款 - 使用OpenAI的API從較大型號中提取較大型號的數據來培訓較小的模型。 Openai證實了它對中國和其他公司複製領導美國AI模型的這種嚐試的認識,並表示其致力於保護其知識產權的承諾。
唐納德·特朗普(Donald Trump)的AI顧問戴維·薩克斯(David Sacks)證實了Openai的懷疑,這表明DeepSeek的行動涉及未經授權從Openai模型中提取知識。他預計,領先的AI公司將采取措施,以防止將來的數據蒸餾實例。
這種情況強調了一個重要的諷刺意味:Openai本身麵臨著使用受版權保護的材料未經授權而開發Chatgpt的指控。這種偽善在社交媒體上被廣泛注意到,批評家指出,Openai先前的斷言,即創建沒有版權材料的Chatgpt之類的AI工具是“不可能的”。 Openai捍衛了自己的做法,理由是培訓大語言模型的必要條件,並認為其使用構成了“合理使用”。紐約時報和17位作者提起訴訟,目前正受到挑戰,指控侵犯版權。圍繞AI培訓數據和版權的法律景觀仍然引起了極大的爭議,特別是鑒於2018年美國版權所有裁決,即AI生成的藝術沒有資格獲得版權保護。