

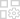






Chatgpt Maker vermoedt dat China's vuil goedkope Deepseek AI -modellen zijn gebouwd met behulp van OpenAI -gegevens - en de ironie gaat niet verloren op internet
Openai vermoedt dat de diepe AI -modellen van China, aanzienlijk goedkoper dan westerse tegenhangers, mogelijk zijn getraind met behulp van OpenAI -gegevens, het veroorzaken van controverse en onrust op de markt. De opkomst van Deepseek, en zijn R1-model, veroorzaakte specifiek een dramatische daling van de aandelenkoersen van grote AI-gerelateerde bedrijven, waarbij NVIDIA het grootste verlies van een enkele dag in de geschiedenis ondervond. Deepseek beweert dat de lage trainingskosten van zijn model ($ 6 miljoen) en verminderde rekenbehoeften te wijten zijn aan de open-source Deepseek-V3 Foundation.
Deze ontwikkeling heeft bezorgdheid geuit over de enorme investeringen die Amerikaanse technologiebedrijven in AI binnenstromen, waardoor investeerdersaanval wordt aangevoerd. De populariteit van Deepseek, die ons App Download -grafieken snel stond, heeft deze angsten verder gevoed. OpenAI en Microsoft onderzoeken of Deepseek de servicevoorwaarden van Openai heeft geschonden door een techniek te gebruiken genaamd "destillatie" - gegevens extraheren uit grotere modellen om kleinere te trainen - met behulp van de API van Openai. Openai bevestigde zijn bewustzijn van dergelijke pogingen van Chinese en andere bedrijven om het leiden van ons AI -modellen te repliceren en verklaarde zijn toewijding om zijn intellectuele eigendom te beschermen.
De AI -adviseur van Donald Trump, David Sacks, bevestigde de vermoedens van Openai, wat suggereert dat de acties van Deepseek de ongeautoriseerde extractie van kennis uit Openai -modellen betrof. Hij verwacht dat toonaangevende AI -bedrijven maatregelen zullen implementeren om toekomstige gevallen van gegevensdistillatie te voorkomen.
De situatie benadrukt een belangrijke ironie: Openai zelf heeft te maken gehad met beschuldigingen van het gebruik van auteursrechtelijk beschermd materiaal zonder toestemming in de ontwikkeling van Chatgpt. Deze hypocrisie is algemeen opgemerkt op sociale media, waarbij critici wijzen op de eerdere bewering van Openai dat het creëren van AI -tools zoals Chatgpt zonder auteursrechtelijk beschermd materiaal "onmogelijk" is. Openai heeft zijn praktijken verdedigd, onder verwijzing naar het uitgebreide gebruik van auteursrechtelijk beschermd materiaal, indien nodig voor het trainen van grote taalmodellen en het argumenteren dat het gebruik ervan 'redelijk gebruik' is. Deze claim wordt momenteel aangevochten in rechtszaken die zijn aangespannen door de New York Times en 17 auteurs, die beweren dat inbreuk op het auteursrecht. Het juridische landschap rondom AI-trainingsgegevens en het auteursrecht blijft sterk betwist, met name in het licht van een uitspraak van de US Copyright Office 2018 dat AI-gegenereerde kunst niet in aanmerking komt voor auteursrechtbescherming.

-
 Dec 25,24Zenless Zone Zero 1.5 updatevoorbeeld Update Zenless Zone Zero versie 1.5: gelekte bannerkarakters onthuld Nieuwe lekken voor Zenless Zone Zero onthullen de personagereeks voor de komende versie 1.5-update, inclusief langverwachte personageherhalingen. Deze HoYoverse actie-RPG blijft zijn selectie krachtige personages uitbreiden, fr
Dec 25,24Zenless Zone Zero 1.5 updatevoorbeeld Update Zenless Zone Zero versie 1.5: gelekte bannerkarakters onthuld Nieuwe lekken voor Zenless Zone Zero onthullen de personagereeks voor de komende versie 1.5-update, inclusief langverwachte personageherhalingen. Deze HoYoverse actie-RPG blijft zijn selectie krachtige personages uitbreiden, fr -
 May 06,25Magic Chess: Beginner's Guide to Mastering Core Mechanics Magic Chess: Go Go, een opwindende Auto-Battler-strategiespel gemaakt door Moonton, is diep geworteld in het levendige universum van mobiele legendes. Deze game combineert meesterlijk schaaktactieken met op held gebaseerde strategieën en biedt spelers de kans om formidabele teamline-ups te maken met helden van TH
May 06,25Magic Chess: Beginner's Guide to Mastering Core Mechanics Magic Chess: Go Go, een opwindende Auto-Battler-strategiespel gemaakt door Moonton, is diep geworteld in het levendige universum van mobiele legendes. Deze game combineert meesterlijk schaaktactieken met op held gebaseerde strategieën en biedt spelers de kans om formidabele teamline-ups te maken met helden van TH -
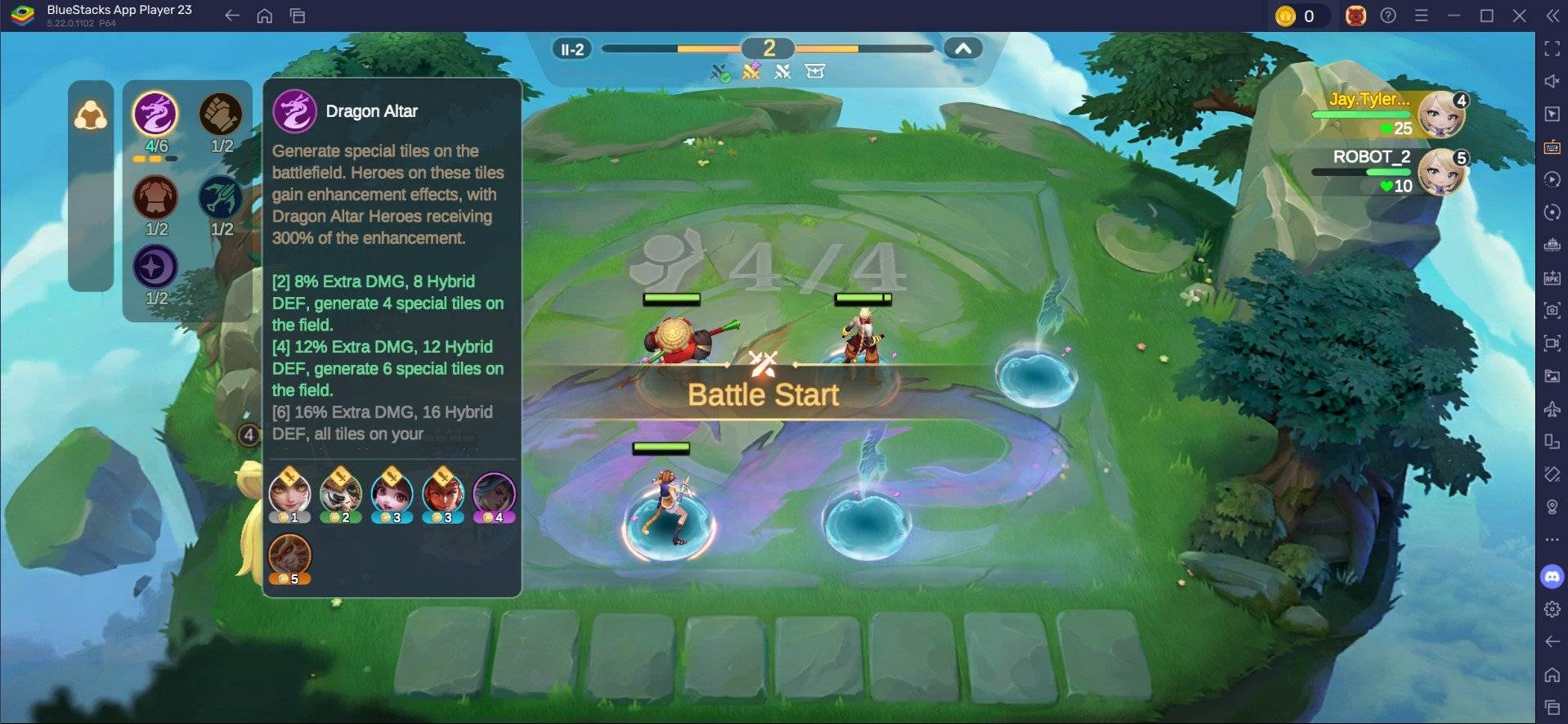
 Jan 18,25Roblox Grace: alle opdrachten en hoe u ze kunt gebruiken Snelle linksAlle Grace-commando'sGrace-commando's gebruikenGrace is een Roblox-ervaring waarbij je door verschillende niveaus moet navigeren terwijl enge entiteiten op je wachten. Deze game is behoorlijk uitdagend, omdat je snel moet zijn en snel moet reageren, en moet zoeken naar manieren om de entiteit tegen te gaan.
Jan 18,25Roblox Grace: alle opdrachten en hoe u ze kunt gebruiken Snelle linksAlle Grace-commando'sGrace-commando's gebruikenGrace is een Roblox-ervaring waarbij je door verschillende niveaus moet navigeren terwijl enge entiteiten op je wachten. Deze game is behoorlijk uitdagend, omdat je snel moet zijn en snel moet reageren, en moet zoeken naar manieren om de entiteit tegen te gaan. -
 Apr 11,25"Top Heroes Tier List for Puzzles & Survival in 2025" Een Tier -lijst voor Puzzles & Survival is een essentieel hulpmiddel voor spelers die hun gameplay willen optimaliseren. Het helpt bij het identificeren van de meest effectieve helden voor verschillende spelmodi, zoals Match-3-gevechten, basisverdediging en PVP-gevechten. Gezien de brede reeks helden van het spel, rangschik ze volgens th
Apr 11,25"Top Heroes Tier List for Puzzles & Survival in 2025" Een Tier -lijst voor Puzzles & Survival is een essentieel hulpmiddel voor spelers die hun gameplay willen optimaliseren. Het helpt bij het identificeren van de meest effectieve helden voor verschillende spelmodi, zoals Match-3-gevechten, basisverdediging en PVP-gevechten. Gezien de brede reeks helden van het spel, rangschik ze volgens th