

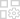






ChatGPT Maker Suspects China’s Dirt Cheap DeepSeek AI Models Were Built Using OpenAI Data — and the Irony Is Not Lost on the Internet
OpenAI suspects that China's DeepSeek AI models, significantly cheaper than Western counterparts, may have been trained using OpenAI data, sparking controversy and market turmoil. The emergence of DeepSeek, and its R1 model specifically, caused a dramatic drop in the stock prices of major AI-related companies, with Nvidia experiencing its largest single-day loss in history. DeepSeek claims its model's low training cost ($6 million) and reduced computational needs are due to its open-source DeepSeek-V3 foundation.
This development has raised concerns about the massive investments American tech companies are pouring into AI, prompting investor apprehension. The popularity of DeepSeek, which quickly topped US app download charts, further fueled these anxieties. OpenAI and Microsoft are investigating whether DeepSeek violated OpenAI's terms of service by employing a technique called "distillation" – extracting data from larger models to train smaller ones – using OpenAI's API. OpenAI confirmed its awareness of such attempts by Chinese and other companies to replicate leading US AI models and stated its commitment to protecting its intellectual property.
Donald Trump's AI advisor, David Sacks, corroborated OpenAI's suspicions, suggesting that DeepSeek's actions involved the unauthorized extraction of knowledge from OpenAI models. He anticipates that leading AI companies will implement measures to prevent future instances of data distillation.
The situation highlights a significant irony: OpenAI itself has faced accusations of using copyrighted material without authorization in the development of ChatGPT. This hypocrisy has been widely noted on social media, with critics pointing to OpenAI's previous assertion that creating AI tools like ChatGPT without copyrighted material is "impossible." OpenAI has defended its practices, citing the extensive use of copyrighted material as necessary for training large language models and arguing that its use constitutes "fair use." This claim is currently being challenged in lawsuits filed by the New York Times and 17 authors, alleging copyright infringement. The legal landscape surrounding AI training data and copyright remains highly contested, particularly in light of a 2018 US Copyright Office ruling that AI-generated art is not eligible for copyright protection.

-
 Dec 25,24Zenless Zone Zero 1.5 Update Preview Zenless Zone Zero Version 1.5 Update: Leaked Banner Characters Revealed New leaks for Zenless Zone Zero unveil the character lineup for the upcoming Version 1.5 update, including highly anticipated character reruns. This HoYoverse action RPG continues to expand its roster of powerful characters, fr
Dec 25,24Zenless Zone Zero 1.5 Update Preview Zenless Zone Zero Version 1.5 Update: Leaked Banner Characters Revealed New leaks for Zenless Zone Zero unveil the character lineup for the upcoming Version 1.5 update, including highly anticipated character reruns. This HoYoverse action RPG continues to expand its roster of powerful characters, fr -
 May 06,25Magic Chess: Beginner's Guide to Mastering Core Mechanics Magic Chess: Go Go, an exhilarating auto-battler strategy game crafted by Moonton, is deeply rooted in the vibrant universe of Mobile Legends. This game masterfully blends chess tactics with hero-based strategies, offering players the chance to craft formidable team line-ups featuring heroes from th
May 06,25Magic Chess: Beginner's Guide to Mastering Core Mechanics Magic Chess: Go Go, an exhilarating auto-battler strategy game crafted by Moonton, is deeply rooted in the vibrant universe of Mobile Legends. This game masterfully blends chess tactics with hero-based strategies, offering players the chance to craft formidable team line-ups featuring heroes from th -
 Apr 08,25Top Free Fire Characters 2025: Ultimate Guide Free Fire, crafted by Garena, has cemented its status as a top-tier battle royale game worldwide, amassing over 1 billion downloads on the Google Play Store and engaging millions of daily active players. Its appeal lies not only in its thrilling gameplay but also in its diverse array of characters,
Apr 08,25Top Free Fire Characters 2025: Ultimate Guide Free Fire, crafted by Garena, has cemented its status as a top-tier battle royale game worldwide, amassing over 1 billion downloads on the Google Play Store and engaging millions of daily active players. Its appeal lies not only in its thrilling gameplay but also in its diverse array of characters, -
 Jan 18,25Roblox Grace: All Commands and How to Use Them Grace 游戏指令速查 所有 Grace 指令 如何使用 Grace 指令 Grace 是一款 Roblox 游戏,玩家需要在充满恐怖生物的各个关卡中生存。游戏极具挑战性,需要玩家快速反应并寻找对抗敌人的方法。幸运的是,开发人员添加了测试服务器功能,玩家可以使用聊天指令来简化游戏,召唤敌人,或进行游戏测试。以下列出了 Grace 游戏中的所有指令以及使用方法。 所有 Grace 指令 .revive:复活指令,用于在失败或卡住时重新进入游戏。 .panicspeed:修改计时器速度。 .dozer:召唤 Dozer 实体。 .main:进入主分支服务器。 .slugfish:召唤 S
Jan 18,25Roblox Grace: All Commands and How to Use Them Grace 游戏指令速查 所有 Grace 指令 如何使用 Grace 指令 Grace 是一款 Roblox 游戏,玩家需要在充满恐怖生物的各个关卡中生存。游戏极具挑战性,需要玩家快速反应并寻找对抗敌人的方法。幸运的是,开发人员添加了测试服务器功能,玩家可以使用聊天指令来简化游戏,召唤敌人,或进行游戏测试。以下列出了 Grace 游戏中的所有指令以及使用方法。 所有 Grace 指令 .revive:复活指令,用于在失败或卡住时重新进入游戏。 .panicspeed:修改计时器速度。 .dozer:召唤 Dozer 实体。 .main:进入主分支服务器。 .slugfish:召唤 S