

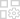






Chatgpt Maker podejrzewa, że brud w chińskich tanich modelach AI Deepseek zostały zbudowane przy użyciu danych Openai - a ironia nie jest utracona w Internecie
Openai podejrzewa, że modele Deepeek AI w Chinach, znacznie tańsze niż zachodnie odpowiednicy, mogły zostać przeszkolone przy użyciu danych OpenAI, wywołując kontrowersje i zamieszanie rynkowe. Pojawienie się Deepseek i jego modelu R1 w szczególności spowodowało dramatyczny spadek cen akcji dużych spółek związanych z AI, a Nvidia doświadczyła największej jednodniowej straty w historii. Deepseek twierdzi, że niski koszt szkolenia swojego modelu (6 milionów dolarów), a zmniejszone potrzeby obliczeniowe wynikają z fundacji Deepseek-V3 z open source.
Rozwój ten wzbudziło obawy dotyczące masowych inwestycji, które amerykańskie firmy technologiczne napływają do sztucznej inteligencji, co skłoniło obawy inwestorów. Popularność Deepseek, która szybko przewyższyła amerykańskie listy przebojów aplikacji, dodatkowo napędzała te lęki. Openai i Microsoft badają, czy Deepseek naruszył warunki usług Openai, stosując technikę o nazwie „destylacja” - wyodrębniając dane z większych modeli w celu szkolenia mniejszych - za pomocą interfejsu API Openai. Openai potwierdził swoją świadomość takich prób chińskiego i innych firm w celu powtórzenia wiodących amerykańskich modeli AI i stwierdził swoje zaangażowanie w ochronę własności intelektualnej.
Doradca AI Donalda Trumpa, David Sacks, potwierdził podejrzenia Openai, sugerując, że działania Deepseeka obejmowały nieautoryzowane wydobycie wiedzy z modeli Openai. Oczekuje, że wiodące firmy AI wdrażają środki zapobiegające przyszłym przypadkom destylacji danych.
Sytuacja podkreśla znaczącą ironię: sam Openai spotkał się z oskarżeniami o użycie materiału chronionego prawem autorskim bez upoważnienia do rozwoju Chatgpt. Ta hipokryzja została powszechnie odnotowana w mediach społecznościowych, a krytycy wskazują na poprzednie twierdzenie Openai, że tworzenie narzędzi AI, takich jak Chatgpt bez materiału chronionego prawem autorskim, jest „niemożliwe”. Openai bronił swoich praktyk, powołując się na szerokie stosowanie materiałów chronionych prawem autorskim, które jest konieczne do szkolenia dużych modeli językowych i argumentując, że jego użycie stanowi „dozwolone użycie”. Roszczenie to jest obecnie kwestionowane w pozwach złożonych przez New York Times i 17 autorów, zarzucając naruszeniu praw autorskich. Prawny krajobraz dotyczący danych szkoleniowych i praw autorskich pozostaje wysoce kwestionowany, szczególnie w świetle orzeczenia w sprawie praw autorskich w USA w 2018 r., Że sztuka generowana przez AI nie kwalifikuje się do ochrony praw autorskich.

-
 Dec 25,24Podgląd aktualizacji Zenless Zone Zero 1.5 Aktualizacja Zenless Zone Zero w wersji 1.5: ujawniono postacie z banerów, które wyciekły Nowe przecieki dotyczące Zenless Zone Zero ujawniają skład postaci w nadchodzącej aktualizacji wersji 1.5, w tym wyczekiwane powtórki postaci. Ta gra RPG akcji HoYoverse stale poszerza gamę potężnych postaci, fr
Dec 25,24Podgląd aktualizacji Zenless Zone Zero 1.5 Aktualizacja Zenless Zone Zero w wersji 1.5: ujawniono postacie z banerów, które wyciekły Nowe przecieki dotyczące Zenless Zone Zero ujawniają skład postaci w nadchodzącej aktualizacji wersji 1.5, w tym wyczekiwane powtórki postaci. Ta gra RPG akcji HoYoverse stale poszerza gamę potężnych postaci, fr -
 May 06,25Magic Chess: Przewodnik dla początkujących po masterowaniu mechaniki podstawowej Magic Chess: Go, radosna gra strategiczna auto-battlera wykonana przez Moontona, jest głęboko zakorzeniona w żywym wszechświecie mobilnych legend. Ta gra po mistrzowsku łączy taktykę szachową ze strategiami opartymi na bohaterach, oferując graczom szansę na stworzenie potężnych ofert zespołowych z bohaterami TH
May 06,25Magic Chess: Przewodnik dla początkujących po masterowaniu mechaniki podstawowej Magic Chess: Go, radosna gra strategiczna auto-battlera wykonana przez Moontona, jest głęboko zakorzeniona w żywym wszechświecie mobilnych legend. Ta gra po mistrzowsku łączy taktykę szachową ze strategiami opartymi na bohaterach, oferując graczom szansę na stworzenie potężnych ofert zespołowych z bohaterami TH -
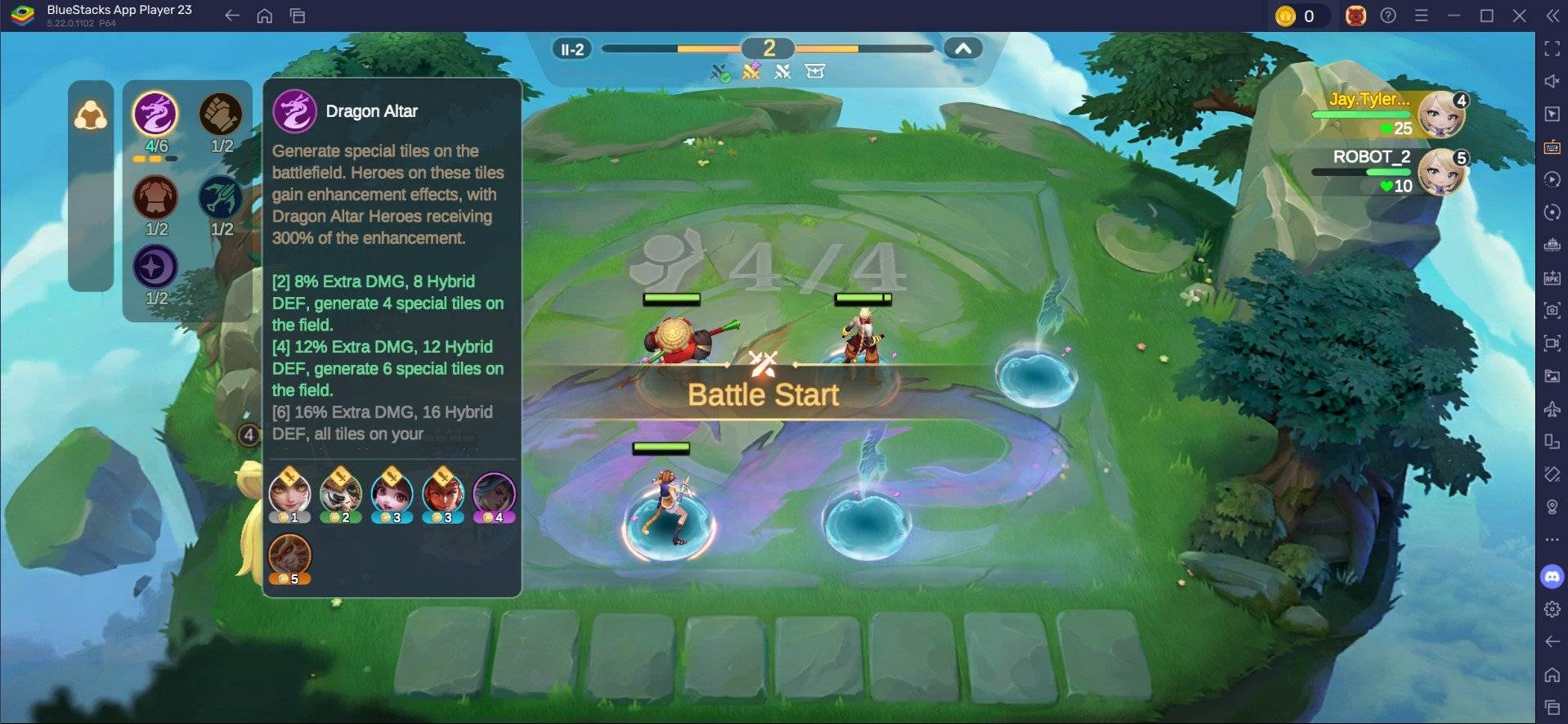
 Jan 18,25Roblox Łaska: wszystkie polecenia i jak z nich korzystać Szybkie linkiWszystkie polecenia GraceJak korzystać z poleceń GraceGrace to gra Roblox, w której będziesz musiał poruszać się po różnych poziomach z czekającymi na ciebie przerażającymi istotami. Ta gra jest dość wymagająca, ponieważ musisz być szybki i szybko reagować, a także szukać sposobów na przeciwdziałanie podmiotowi
Jan 18,25Roblox Łaska: wszystkie polecenia i jak z nich korzystać Szybkie linkiWszystkie polecenia GraceJak korzystać z poleceń GraceGrace to gra Roblox, w której będziesz musiał poruszać się po różnych poziomach z czekającymi na ciebie przerażającymi istotami. Ta gra jest dość wymagająca, ponieważ musisz być szybki i szybko reagować, a także szukać sposobów na przeciwdziałanie podmiotowi -
 Apr 11,25„Lista poziomów najlepszych bohaterów dla zagadek i przetrwania w 2025 r.” Lista poziomów dla zagadek i przetrwania jest niezbędnym narzędziem dla graczy, którzy chcą zoptymalizować swoją rozgrywkę. Pomaga w identyfikacji najskuteczniejszych bohaterów dla różnych trybów gry, takich jak bitwy meczowe, obrona podstawowa i walka z PVP. Biorąc pod uwagę szeroki wachlarz bohaterów gry, według nich według nich
Apr 11,25„Lista poziomów najlepszych bohaterów dla zagadek i przetrwania w 2025 r.” Lista poziomów dla zagadek i przetrwania jest niezbędnym narzędziem dla graczy, którzy chcą zoptymalizować swoją rozgrywkę. Pomaga w identyfikacji najskuteczniejszych bohaterów dla różnych trybów gry, takich jak bitwy meczowe, obrona podstawowa i walka z PVP. Biorąc pod uwagę szeroki wachlarz bohaterów gry, według nich według nich