

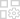






CHATGPT निर्माता को संदेह है कि चीन की गंदगी सस्ते डीपसेक एआई मॉडल ओपनईएआई डेटा का उपयोग करके बनाया गया था - और विडंबना इंटरनेट पर नहीं खोई है
Openai को संदेह है कि चीन के डीपसेक एआई मॉडल, पश्चिमी समकक्षों की तुलना में काफी सस्ते, ओपनईएआई डेटा, स्पार्किंग विवाद और बाजार की उथल -पुथल का उपयोग करके प्रशिक्षित किया जा सकता है। दीपसेक के उद्भव, और इसके आर 1 मॉडल ने विशेष रूप से, प्रमुख एआई-संबंधित कंपनियों के स्टॉक की कीमतों में एक नाटकीय गिरावट का कारण बना, जिसमें एनवीडिया इतिहास में अपने सबसे बड़े एकल-दिवसीय नुकसान का अनुभव कर रहा था। दीपसेक का दावा है कि इसके मॉडल की कम प्रशिक्षण लागत ($ 6 मिलियन) और कम कम्प्यूटेशनल आवश्यकताएं इसके ओपन-सोर्स डीपसेक-वी 3 फाउंडेशन के कारण हैं।
इस विकास ने बड़े पैमाने पर निवेश के बारे में चिंता जताई है जो अमेरिकी टेक कंपनियां एआई में डाल रही हैं, जिससे निवेशक आशंका पैदा हो रही है। दीपसेक की लोकप्रियता, जो जल्दी से यूएस ऐप डाउनलोड चार्ट में सबसे ऊपर है, ने इन चिंताओं को और बढ़ा दिया। Openai और Microsoft यह जांच कर रहे हैं कि क्या दीपसेक ने "डिस्टिलेशन" नामक एक तकनीक को नियोजित करके Openai की सेवा की शर्तों का उल्लंघन किया है - छोटे मॉडल से डेटा निकालने के लिए छोटे लोगों को प्रशिक्षित करने के लिए - Openai के API का उपयोग करना। Openai ने चीनी और अन्य कंपनियों द्वारा इस तरह के प्रयासों के बारे में अपनी जागरूकता की पुष्टि की कि वे प्रमुख अमेरिकी AI मॉडल को दोहराने के लिए और अपनी बौद्धिक संपदा की रक्षा के लिए अपनी प्रतिबद्धता बताई।
डोनाल्ड ट्रम्प के एआई सलाहकार, डेविड सैक्स ने ओपनई के संदेह को पुष्टि की, यह सुझाव देते हुए कि दीपसेक के कार्यों में ओपनईई मॉडल से ज्ञान के अनधिकृत निष्कर्षण को शामिल किया गया था। वह अनुमान लगाता है कि प्रमुख एआई कंपनियां डेटा आसवन के भविष्य के उदाहरणों को रोकने के लिए उपायों को लागू करेंगी।
स्थिति एक महत्वपूर्ण विडंबना को उजागर करती है: ओपनई ने खुद को CHATGPT के विकास में प्राधिकरण के बिना कॉपीराइट सामग्री का उपयोग करने के आरोपों का सामना किया है। इस पाखंड को सोशल मीडिया पर व्यापक रूप से नोट किया गया है, आलोचकों ने ओपनईआई के पिछले दावे की ओर इशारा किया है कि कॉपीराइट सामग्री के बिना चैटगिप जैसे एआई उपकरण बनाना "असंभव" है। Openai ने अपनी प्रथाओं का बचाव किया है, कॉपीराइट सामग्री के व्यापक उपयोग का हवाला देते हुए बड़े भाषा मॉडल को प्रशिक्षित करने और यह तर्क देते हुए कि इसका उपयोग "उचित उपयोग" का गठन करता है। इस दावे को वर्तमान में न्यूयॉर्क टाइम्स और 17 लेखकों द्वारा दायर मुकदमों में चुनौती दी जा रही है, जिसमें कॉपीराइट उल्लंघन का आरोप लगाया गया है। एआई प्रशिक्षण डेटा और कॉपीराइट के आसपास का कानूनी परिदृश्य अत्यधिक चुनाव लड़ा गया है, विशेष रूप से 2018 के अमेरिकी कॉपीराइट कार्यालय के प्रकाश में यह है कि एआई-जनित कला कॉपीराइट संरक्षण के लिए पात्र नहीं है।

-
 Dec 25,24ज़ेनलेस ज़ोन ज़ीरो 1.5 अपडेट पूर्वावलोकन ज़ेनलेस ज़ोन ज़ीरो संस्करण 1.5 अपडेट: लीक हुए बैनर पात्रों का खुलासा ज़ेनलेस ज़ोन ज़ीरो के नए लीक ने आगामी संस्करण 1.5 अपडेट के लिए कैरेक्टर लाइनअप का खुलासा किया है, जिसमें बहुप्रतीक्षित कैरेक्टर रीरन भी शामिल है। यह होयोवर्स एक्शन आरपीजी अपने शक्तिशाली पात्रों की सूची का विस्तार करना जारी रखता है
Dec 25,24ज़ेनलेस ज़ोन ज़ीरो 1.5 अपडेट पूर्वावलोकन ज़ेनलेस ज़ोन ज़ीरो संस्करण 1.5 अपडेट: लीक हुए बैनर पात्रों का खुलासा ज़ेनलेस ज़ोन ज़ीरो के नए लीक ने आगामी संस्करण 1.5 अपडेट के लिए कैरेक्टर लाइनअप का खुलासा किया है, जिसमें बहुप्रतीक्षित कैरेक्टर रीरन भी शामिल है। यह होयोवर्स एक्शन आरपीजी अपने शक्तिशाली पात्रों की सूची का विस्तार करना जारी रखता है -
 May 06,25मैजिक शतरंज: कोर मैकेनिक्स में महारत हासिल करने के लिए बिगिनर गाइड मैजिक शतरंज: गो गो, एक शानदार ऑटो-बैटलर स्ट्रेटेजी स्ट्रेटेजी गेम जो मूनटन द्वारा तैयार किया गया है, मोबाइल किंवदंतियों के जीवंत ब्रह्मांड में गहराई से निहित है। यह गेम हीरो-आधारित रणनीतियों के साथ शतरंज की रणनीति का मिश्रण करता है, जिससे खिलाड़ियों को वें से नायकों की विशेषता वाले दुर्जेय टीम लाइन-अप को शिल्प करने का मौका मिलता है
May 06,25मैजिक शतरंज: कोर मैकेनिक्स में महारत हासिल करने के लिए बिगिनर गाइड मैजिक शतरंज: गो गो, एक शानदार ऑटो-बैटलर स्ट्रेटेजी स्ट्रेटेजी गेम जो मूनटन द्वारा तैयार किया गया है, मोबाइल किंवदंतियों के जीवंत ब्रह्मांड में गहराई से निहित है। यह गेम हीरो-आधारित रणनीतियों के साथ शतरंज की रणनीति का मिश्रण करता है, जिससे खिलाड़ियों को वें से नायकों की विशेषता वाले दुर्जेय टीम लाइन-अप को शिल्प करने का मौका मिलता है -
 Jan 18,25Roblox अनुग्रह: सभी आदेश और उनका उपयोग कैसे करें त्वरित लिंकसभी ग्रेस कमांड ग्रेस कमांड का उपयोग कैसे करें ग्रेस एक रोबॉक्स अनुभव है जहां आपको डरावनी संस्थाओं के साथ विभिन्न स्तरों के माध्यम से नेविगेट करना होगा जो आपकी प्रतीक्षा कर रहे हैं। यह गेम काफी चुनौतीपूर्ण है, क्योंकि आपको त्वरित होने और तेजी से प्रतिक्रिया करने की आवश्यकता होगी, साथ ही एंटिट का प्रतिकार करने के तरीकों की तलाश करनी होगी
Jan 18,25Roblox अनुग्रह: सभी आदेश और उनका उपयोग कैसे करें त्वरित लिंकसभी ग्रेस कमांड ग्रेस कमांड का उपयोग कैसे करें ग्रेस एक रोबॉक्स अनुभव है जहां आपको डरावनी संस्थाओं के साथ विभिन्न स्तरों के माध्यम से नेविगेट करना होगा जो आपकी प्रतीक्षा कर रहे हैं। यह गेम काफी चुनौतीपूर्ण है, क्योंकि आपको त्वरित होने और तेजी से प्रतिक्रिया करने की आवश्यकता होगी, साथ ही एंटिट का प्रतिकार करने के तरीकों की तलाश करनी होगी -
 Apr 11,25"2025 में पहेली और उत्तरजीविता के लिए शीर्ष नायकों की सूची" पहेली और उत्तरजीविता के लिए एक स्तरीय सूची अपने गेमप्ले को अनुकूलित करने के लिए देख रहे खिलाड़ियों के लिए एक आवश्यक उपकरण है। यह विभिन्न गेम मोड के लिए सबसे प्रभावी नायकों की पहचान करने में मदद करता है, जैसे कि मैच -3 लड़ाई, आधार रक्षा और पीवीपी कॉम्बैट। खेल के व्यापक सरणी को देखते हुए, उन्हें वें के अनुसार रैंकिंग
Apr 11,25"2025 में पहेली और उत्तरजीविता के लिए शीर्ष नायकों की सूची" पहेली और उत्तरजीविता के लिए एक स्तरीय सूची अपने गेमप्ले को अनुकूलित करने के लिए देख रहे खिलाड़ियों के लिए एक आवश्यक उपकरण है। यह विभिन्न गेम मोड के लिए सबसे प्रभावी नायकों की पहचान करने में मदद करता है, जैसे कि मैच -3 लड़ाई, आधार रक्षा और पीवीपी कॉम्बैट। खेल के व्यापक सरणी को देखते हुए, उन्हें वें के अनुसार रैंकिंग