

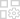






El fabricante de chatgpt sospecha que se construyeron los modelos de AI profundos y baratos de China utilizando datos de OpenAI, y la ironía no se pierde en Internet
Operai sospecha que los modelos de AI profundos de China, significativamente más baratos que las contrapartes occidentales, pueden haber sido entrenados utilizando datos de OpenAI, generos de controversia y agitación del mercado. La aparición de Deepseek, y su modelo R1 específicamente, causaron una caída dramática en los precios de las acciones de las principales empresas relacionadas con la IA, con Nvidia experimentando su mayor pérdida de la historia de un solo día. Deepseek afirma que el bajo costo de capacitación de su modelo ($ 6 millones) y las necesidades computacionales reducidas se deben a su base de código abierto Deepseek-V3.
Este desarrollo ha generado preocupaciones sobre las inversiones masivas que las compañías tecnológicas estadounidenses están llegando a la IA, lo que provocó la aprehensión de los inversores. La popularidad de Deepseek, que rápidamente superó a los gráficos de descarga de la aplicación, alimentó aún más estas ansiedades. Operai y Microsoft están investigando si Deepseek violó los términos de servicio de OpenAI al emplear una técnica llamada "destilación", extrayendo datos de modelos más grandes para capacitar a los más pequeños, utilizando la API de OpenAI. Operai confirmó su conciencia de tales intentos por parte de los chinos y otras compañías de replicar modelos de IA de EE. UU. Y declaró su compromiso de proteger su propiedad intelectual.
El asesor de IA de Donald Trump, David Sacks, corroboró las sospechas de Openai, lo que sugiere que las acciones de Deepseek involucraron la extracción no autorizada de conocimiento de los modelos Operai. Anticipa que las principales compañías de IA implementarán medidas para evitar futuras instancias de destilación de datos.
La situación destaca una ironía significativa: OpenAi ha enfrentado acusaciones de usar material con derechos de autor sin autorización en el desarrollo de ChatGPT. Esta hipocresía se ha observado ampliamente en las redes sociales, con los críticos que señalan la afirmación previa de Openi de que crear herramientas de IA como ChatGPT sin material con derechos de autor es "imposible". Operai ha defendido sus prácticas, citando el uso extenso del material con derechos de autor según sea necesario para capacitar a grandes modelos de idiomas y argumentando que su uso constituye "uso justo". Este reclamo se está impugnando actualmente en las demandas presentadas por el New York Times y 17 autores, alegando infracción de derechos de autor. El paisaje legal que rodea los datos de capacitación de IA y los derechos de autor sigue siendo altamente disputado, particularmente a la luz de una decisión de la Oficina de Derechos de Autor de los Estados Unidos de 2018 de que el arte generado por IA no es elegible para la protección contra los derechos de autor.

-
 Dec 25,24Vista previa de la actualización Zenless Zone Zero 1.5 Actualización de la versión 1.5 de Zenless Zone Zero: se revelan los personajes del banner filtrado Nuevas filtraciones de Zenless Zone Zero revelan la alineación de personajes para la próxima actualización de la Versión 1.5, incluidas reposiciones de personajes muy esperadas. Este juego de rol de acción de HoYoverse continúa ampliando su lista de poderosos personajes, fr.
Dec 25,24Vista previa de la actualización Zenless Zone Zero 1.5 Actualización de la versión 1.5 de Zenless Zone Zero: se revelan los personajes del banner filtrado Nuevas filtraciones de Zenless Zone Zero revelan la alineación de personajes para la próxima actualización de la Versión 1.5, incluidas reposiciones de personajes muy esperadas. Este juego de rol de acción de HoYoverse continúa ampliando su lista de poderosos personajes, fr. -
 May 06,25Magic Chess: Guía para principiantes para dominar la mecánica del núcleo Magic Chess: Go Go, un estimulante juego de estrategia de pescador automático diseñado por Moonton, está profundamente arraigado en el universo vibrante de las leyendas móviles. Este juego combina magistralmente las tácticas de ajedrez con estrategias basadas en héroes, ofreciendo a los jugadores la oportunidad de crear alineaciones formidables de equipo con héroes de th
May 06,25Magic Chess: Guía para principiantes para dominar la mecánica del núcleo Magic Chess: Go Go, un estimulante juego de estrategia de pescador automático diseñado por Moonton, está profundamente arraigado en el universo vibrante de las leyendas móviles. Este juego combina magistralmente las tácticas de ajedrez con estrategias basadas en héroes, ofreciendo a los jugadores la oportunidad de crear alineaciones formidables de equipo con héroes de th -
 Apr 08,25Personajes de Free Fire 2025: Ultimate Guide Free Fire, elaborado por Garena, ha consolidado su estado como un juego de Battle Royale de primer nivel en todo el mundo, acumulando más de mil millones de descargas en Google Play Store e involucrando a millones de jugadores activos diarios. Su atractivo se encuentra no solo en su emocionante juego sino también en su diversa variedad de personajes,
Apr 08,25Personajes de Free Fire 2025: Ultimate Guide Free Fire, elaborado por Garena, ha consolidado su estado como un juego de Battle Royale de primer nivel en todo el mundo, acumulando más de mil millones de descargas en Google Play Store e involucrando a millones de jugadores activos diarios. Su atractivo se encuentra no solo en su emocionante juego sino también en su diversa variedad de personajes, -
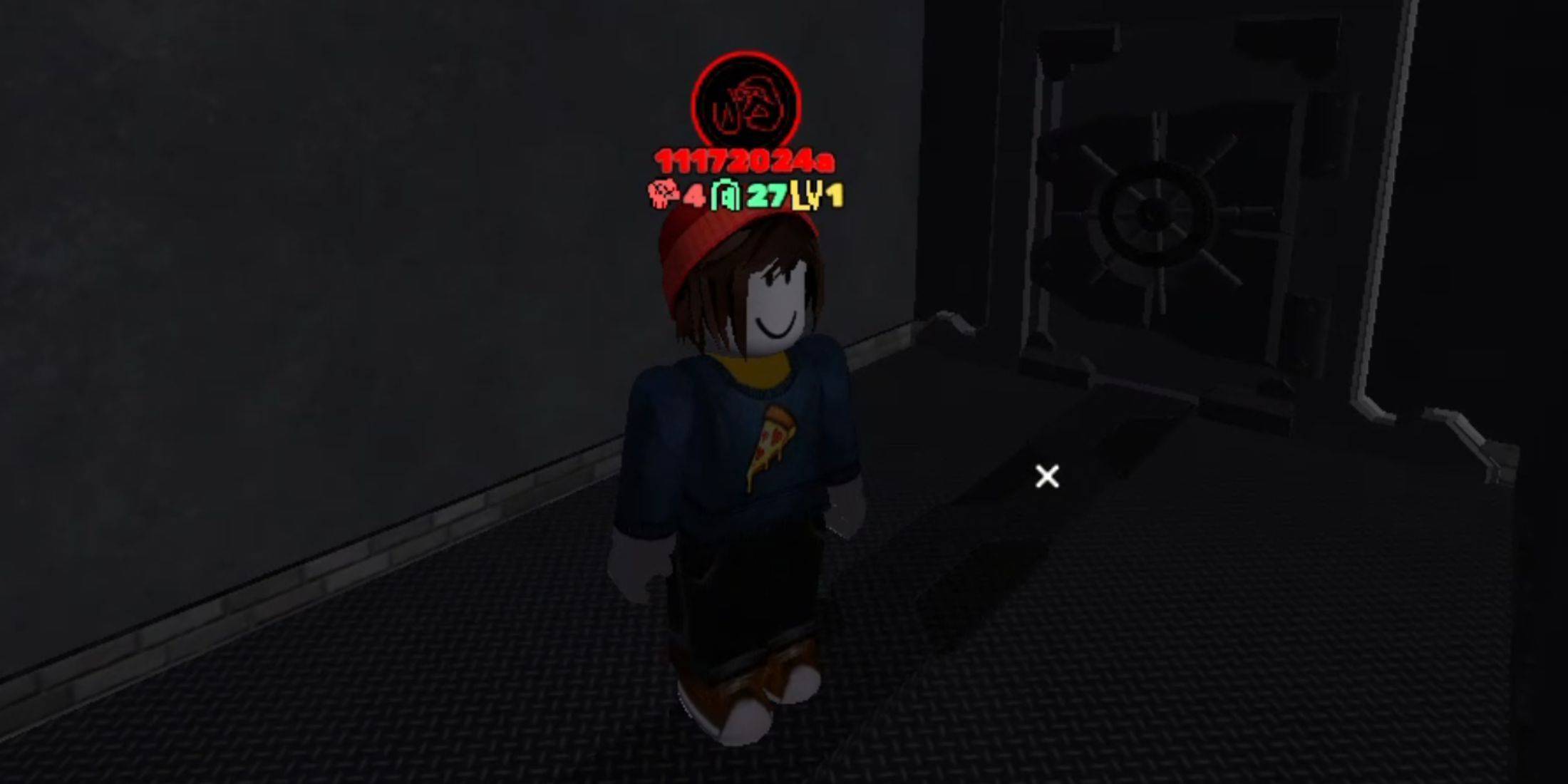 Jan 18,25Roblox Grace: Todos los comandos y cómo usarlos Enlaces rápidosTodos los comandos de GraceCómo usar los comandos de GraceGrace es una experiencia de Roblox en la que tendrás que navegar a través de varios niveles con entidades aterradoras esperándote. Este juego es bastante desafiante, ya que tendrás que ser rápido y reaccionar rápido, además de buscar formas de contrarrestar la entidad.
Jan 18,25Roblox Grace: Todos los comandos y cómo usarlos Enlaces rápidosTodos los comandos de GraceCómo usar los comandos de GraceGrace es una experiencia de Roblox en la que tendrás que navegar a través de varios niveles con entidades aterradoras esperándote. Este juego es bastante desafiante, ya que tendrás que ser rápido y reaccionar rápido, además de buscar formas de contrarrestar la entidad.